Das EMIL API wird nicht mehr weiterentwickelt und entfernt, sobald es keine aktiven Nutzer mehr gibt. Bitte nutzen Sie die Möglichkeiten des über EMMA verfügbaren EMIL Plattform FHIR-Servers, siehe FHIR Server (+) in diesem Kapitel.
RheDAT ermöglicht es, von außerhalb des Systems auf die RheDAT-Datenbank zuzugreifen. Dazu ist für Statistiker die Query-Schnittstelle verfügbar. Einstellungen dazu werden unter Administration|Schnittstellen unter dem Punkt EMIL Plattform API vorgenommen. Für diese Funktionen ist keine Plus-Funktionalität erforderlich.
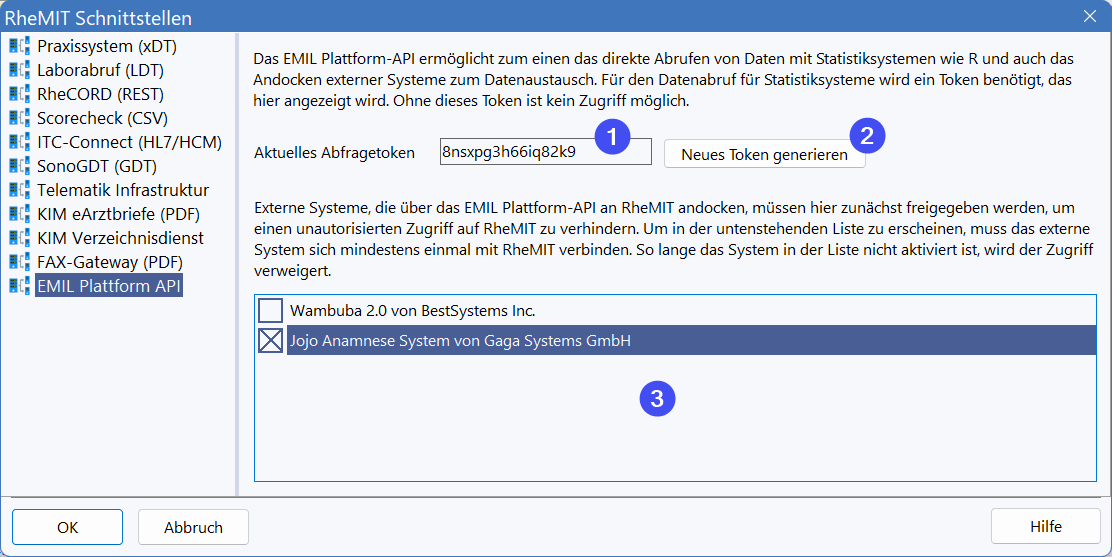
Die Query-Schnittstelle ist für Massendatenabfragen vorgesehen und wurde für die Statistiksysteme wie R, SAS oder SPSS optimiert. Um diese Schnittstelle nutzen zu können, muss der Administrator das Abfragetoken (1) an den Statistiker weitergeben. Besteht der Verdacht, das Token wäre in falsche Hände geraten, kann jederzeit mit (2) ein neues generiert werden.
Bitte beachten Sie, dass das Modul dennoch nicht dafür konzipiert ist, den Inhalt der gesamten RheDAT-Datenbank in CSV-Tabellen zu exportieren. Grundsätzlich ist dies zwar möglich, führt aber zu extrem langen Laufzeiten, hoher Serverlast, sehr hohem Speicherbedarf auf dem Server, was zu Abbrüchen bei der Abfrage führen kann. Daneben kann bei extremen Resultat-Datenmengen keine Garantie dafür übernommen werden, dass die erzeugte Excel-Datei und Excel bei diesen Datenmengen korrekt arbeiten.
Unter (3) können Sie das EMIL Plattform API für eine Anwendung freigeben. Ohne Ihre explizite Freigabe können keine Systeme von außen auf diese Schnittstellen zugreifen. Das Plattform API bietet anderer Software die Möglichkeit, Daten mit RheDAT direkt auszutauschen und ist hier ausführlich beschrieben.
Wichtiges zur Datenstruktur
Um sinnvoll mit der Query-Schnittstelle zu arbeiten, ist ein Verständnis der RheDAT-Datenstrukturen sehr wichtig. Dies gilt gleichermaßen als Grundlage für die Nutzung der Abfrageschnittstelle und für das API für Softwareentwickler. Grundprinzip der Datenhaltung ist das Single Point of Truth Prinzip.
Datenbereiche
RheDAT teilt die Daten in drei Datenbereiche ein.
•Stammdaten sind zusammen mit dem Patienten (Subject) in einer Tabelle gespeichert und haben vorwiegend informativen und identifizierenden Charakter. Beispiele sind Wohnort, Name, Telefonnummer
•Feste Daten sind Daten, die pro Patient nur einmal vorkommen. Sie haben deshalb auch kein Datum. Beispiele sind Anamnese, Geschlecht, Geburtsdatum, Krankenversicherung.
•Verlaufs- und Labordaten sind Daten, die pro Patient mehrfach vorkommen können. Dabei gilt, dass eine Information zu einem Patient und einem Zeitpunkt immer nur einmal existiert. Obwohl dies selbstverständlich klingt, erlauben viele andere Systeme, dieselbe Information an verschiedenen Stellen zu speichern und erlauben damit widersprüchliche Datensituationen. Beispiele für Verlaufs- und Labordaten sind Blutdruck, behandelnder Arzt, CRP, HbA1C.
Da sich feste Daten von den Verlaufs- und Labordaten nur insofern unterscheiden, dass sie kein Datum haben, werden sie technisch gemeinsam als Items betrachtet. Items in RheDAT können verschiedene Datentypen beherbergen wie Zahlenwerte, Text, Listen, Datumsangaben und auch Formulare.
Formulare ermöglichen es, zu einem Item mehrere Detailinformationen zu speichern. Das Item WHO5 beispielsweise, repräsentiert einen Score als Itemwert. Die Fragen, aus denen dieser Score berechnet wird, machen das Formular aus und werden technisch als Subitems betrachtet. Sie werden am Item in einer JSON Datenstruktur gespeichert. Für die Query-Schnittstelle werden diese Subitems in eine zusätzliche Tabelle ausgelagert, da Statistiksysteme erfahrungsgemäß mit JSON Werten in Tabellenspalten nicht gut umgehen können.
Daten abfragen
Anfragen werden über den REST-URL
https://<RheDAT-Server>:8443/query/<token>/<study.1>+<<study.2>+...+<study.n/<item.1>+<item.2>+...+<item.m>
gestellt.
Beachten Sie unbedingt die Netzwerkhinweise unter Netzwerk, DMZ und Firewall wenn der Zugriff von außerhalb des lokalen Netzwerks erfolgen soll.
Abfragen können nicht nur über ein Statistiksystem wie R geschehen, sondern auch mit einem Webbrowser*. Das Token kann der RheDAT-Administrator über die Schnittstellen Konfiguration ermitteln, die IDs der gewünschten Studien und Items können nach dem unter Referenzierung angegebenen Schema ermittelt werden. Soll nicht nach Studien selektiert werden, kann statt der StudienIDs all angegeben werden. Bei Prüfung einer Studienzugehörigkeit wird auf das Merkmal Einwilligung (Consent) geschaut, nicht auf das Vorliegen einer Einschreibung. Ohne Angabe von Items werden nur Stammdaten zurückgeliefert.
Beispiel für Abfrage Daten für Patienten in Studien 1002 und 1003 mit vorliegender Einwilligung (auch wenn sie nicht mehr eingeschrieben sind) für die Items 104, 52190 und 10080:
https://<RheDAT-Server>:8443/query/oweuhfwonu7z47/1002+1003/104+52190+10080
Beispiel für Abfragen alle Patienten ohne Prüfung einer Studienzugehörigkeit für das Item 103 und 104:
https://<RheDAT-Server>:8443/query/oweuhfwonu7z47/all/103+104
Eine Abfrage liefert als Ergebnis ein komprimiertes ZIP Archiv mit mehreren Tabellen. Aus Effizienzgründen werden Daten nicht im Wide-Format, sondern verteilt auf mehrere Tabellen in Long Format geliefert. Es werden Patientenakten mit ihren Stammdaten sowie die im URL angegebenen Items zurückgeliefert. Die Dekodierung kodierter Items ist unter Referenzierung beschrieben, zudem werden die Dekodierungen in der Tabelle codes mitgeliefert.
Die Abfrage kann je nach Datenbestand und abgefragtem Umfang einige Zeit in Anspruch nehmen, bitte haben Sie daher bei einer großen Anzahl von Patientenakten in RheDAT Geduld. Dies gilt insbesondere bei Abfragen Questionnaires mit Unterstrukturen.
Ausgabedaten
Das Zip-Archiv enthält fünf Tabellen im CSV-Format mit Tab als Trennzeichen (ASCII Code 9) und ohne Quote-Character:
Name |
Schlüsselfeld |
Inhalt |
subjects.csv |
subjectid |
Patientennamen mit SUBJECT_ID, Geschlecht und Geburtsdatum, Studienzugehörigkeiten und weiteren Stammdaten |
items.csv |
itemid |
Itemdaten mit Itembezeichnung, Referenzdatum und Wert. Items aus den festen Daten, die nur einmal pro Patient auftreten, werden mit leerem Referenzdatum ausgegeben. Wichtiger Hinweis: Datumsangaben werden als yyyy-mm-dd bzw. als yyyy-mm oder yyyy bei unscharfen Angaben ausgegeben! Bei Visitzeitpunkten ist zusätzlich eine Zeitangabe enthalten. Bei ungenauen numerischen Angaben wird der Wert in der angegebenen Form (z. B. "< 20") ausgegeben. Bei Questionnaires wird hier der in der Zelle sichtbare Text ausgegeben, z.B der Score oder eine textuelle Zusammenfassung. Enthält ein Item mehrere Exemplare eines Questionnaire (z.B. Medikationsangaben), so werden mehrere Zeilen in der Tabelle erzeugt, jeweils eines für jedes Exemplar. Da die interne ItemID für diese Elemente gleich ist, fügt der Export zur Unterscheidung dort einen laufenden Index mit Unterstrich an. Diese Tabelle kann leer sein, wenn keine Items abgefragt werden. |
subitems.csv |
subitemid |
Diese Tabelle referenziert ein Item über die Itemid und enthält alle Questionnaire-Felder mit ihren Werten. Diese Tabelle kann leer sein, wenn keine Questionnaire-Items abgefragt werden. Die Zuordnung der Subitems von Formularen findet sich in der Dokumentation des Datendictionary, die unter Administration|Datendictionary|Dokumentation erzeugt werden kann. Diese Tabelle kann leer sein, wenn keine Formulare abgefragt werden. |
codes.csv |
code |
Diese Tabelle kann leer sein, wenn keine kodierten Items abgefragt werden. |
Beispiel für das System R
Um Daten mit R abzufragen, gehen Sie so vor:
1.Installieren Sie das Paket httr, wenn es noch nicht in Ihrem R System vorhanden ist:
install.packages("httr")
2.Aktivieren Sie es für die Sitzung mit
require(httr)
3.Schalten Sie für diese Sitzung die Prüfung von SSL Zertifikaten aus, da im lokalen Netzwerk mangels Domänennamen keine verifizierbaren Zertifikate eingesetzt werden:
httr::set_config(config(ssl_verifypeer = 0L))
4.Erzeugen Sie den für die Abfrage passenden URL (siehe oben):
url = "https://emilserver:8443/query/8nsxpg3h66iq82k9/all/100+101+104+10190"
5.Fragen Sie den gewünschten Daten von RheDAT ab:
GET(url,write_disk("data.zip",overwrite=TRUE))
6.Extrahieren Sie die Tabellen aus dem Datenpaket
subjects <- read.table(unz("data.zip","subjects.csv"),header=T,sep="\t",quote="")
items <- read.table(unz("data.zip","items.csv"),header=T,sep="\t",quote="")
subitems <- read.table(unz("data.zip","subitems.csv"),header=T,sep="\t",quote="")
codes <- read.table(unz("data.zip","codes.csv"),header=T,sep="\t",quote="")
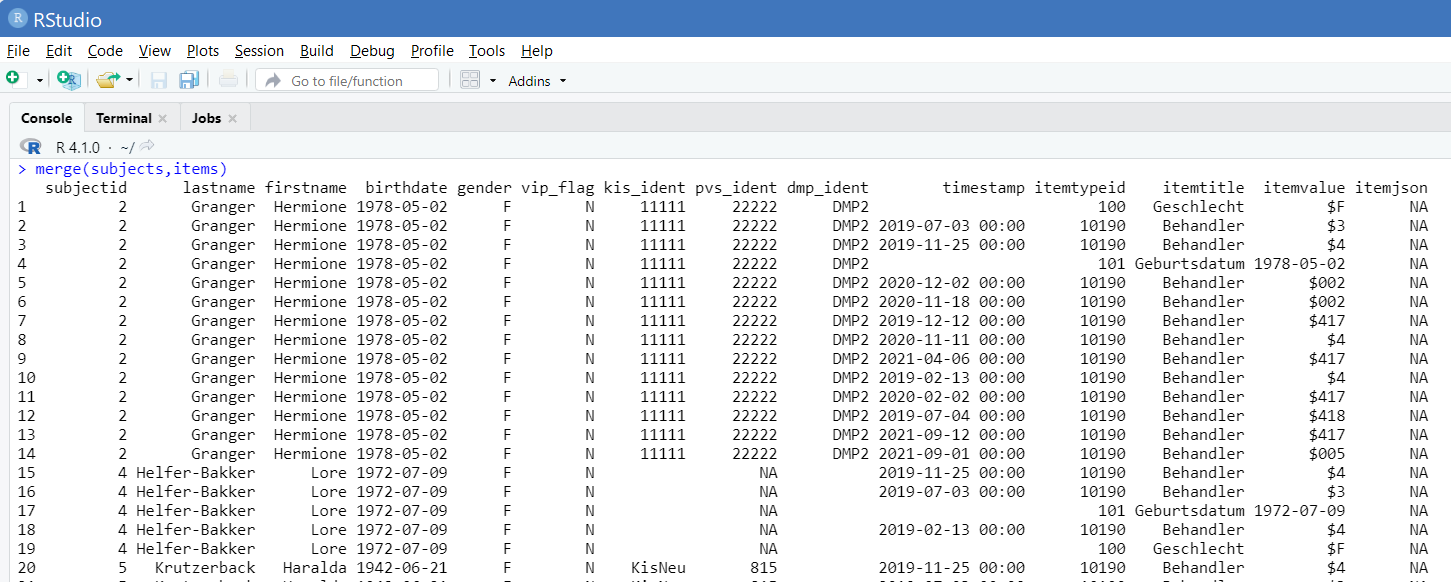
7.Sie können die Tabellen über ihre Schlüssel zusammenführen, R erkennt automatisch diese Verknüpfungen anhand der Schlüsselnamen, die in den jeweiligen Tabellen identisch sind. Ein Beispiel:
merge(subjects,items)
Die Subitems - hier am Beispiel des Itemtype 104 - geben die Inhalte des Questionnaires exakt wieder:
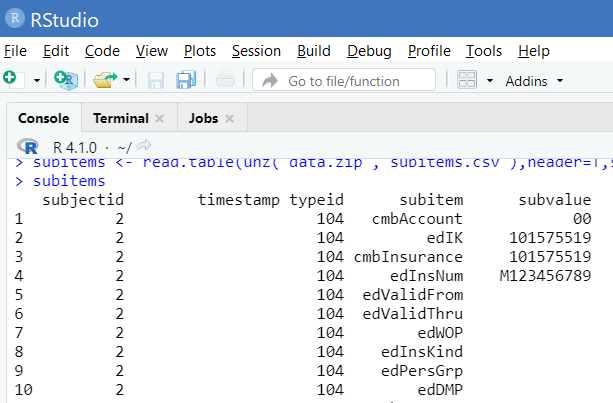
Die Zuordnung der Subitems zu den RheDAT-Questionnaire Feldern findet sich in der Dokumentation des Datendictionary, die unter Administration|Datendictionary|Dokumentation erzeugt werden kann.. Bitte beachten Sie, dass bei Checkboxen, woraus die meisten Questionnaires bestehen, nur die angekreuzten Felder als Subitems übertragen werden!
*Bei Abrufen des ZIP-File mit einem Browser erhalten Sie eine Zertifikatwarnung. Diese rührt daher, dass es in lokalen Netzwerken in der Regel nicht möglich ist, Zertifikate zu erzeugen, die eine Identitätsprüfung erlauben, da dort in aller Regel keine registrierten Domänennamen verwendet werden. Die Verschlüsselung funktioniert mit diesen dort zum Einsatz kommenden, selbst signierten Zertifikaten exakt genauso, wie mit den offiziell ausgestellten, nur erlauben selbst signierte Zertifikate keine Prüfung der Identität des Servers. Während diese Prüfung im Internet absolut wichtig ist, damit Dienste nicht gefälscht werden können, ist dies im lokalen Netzwerk weniger wichtig, da die Systeme dort unter eigener Kontrolle sind.